與其說 匯入 網頁資料,倒不如說已經可以爬網頁資料出來,在做格式化!例如去掉多餘的資訊,未來可轉換成 csv/tsv 等等應用。
官方文件在此:https://support.google.com/docs/answer/3093342?hl=zh-Hant
操作對象:http://www.alexa.com/topsites/countries/TW
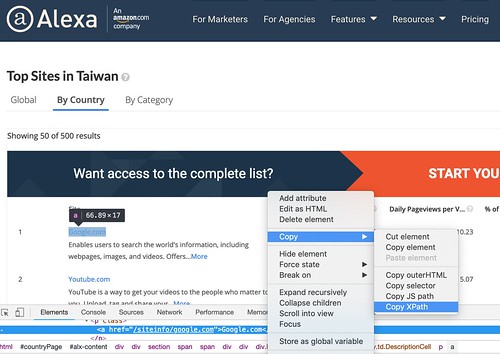
轉換方式:人眼挑戰!或是靠 Chrome browser 檢視元素和 Copy XPath 小改即可
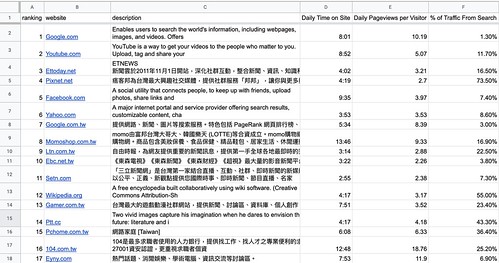
範例 - 網站列表:
- 人眼定位
- =importxml("https://www.alexa.com/topsites/countries/TW","//div/div/div/p/a")
- 透過 Chrome Browser - Copy XPath
- 分析結果:
- //*[@id="alx-content"]/div/div/section[2]/span/span/div/div/div[2]/div[2]/div[2]/p/a"
- 小改:先改到能輸出資料,在去掉指定資料筆數看能不能輸出 array
- //div/div/div[2]/div/div/p/a
本次練習所有欄位都...人眼享受... XD
- =importxml("https://www.alexa.com/topsites/countries/TW","//div[contains(@class, 'site-listing')]/div[contains(@class, 'td')][1]")
- =importxml("https://www.alexa.com/topsites/countries/TW","//div/div/div/p/a")
- =importxml("https://www.alexa.com/topsites/countries/TW","//div[contains(@class, 'description')]/text()[1]")
- =importxml("https://www.alexa.com/topsites/countries/TW","//div[contains(@class, 'site-listing')]/div[contains(@class, 'td') and contains(@class, 'right')][1]")
- =importxml("https://www.alexa.com/topsites/countries/TW","//div[contains(@class, 'site-listing')]/div[contains(@class, 'td') and contains(@class, 'right')][2]")
- =importxml("https://www.alexa.com/topsites/countries/TW","//div[contains(@class, 'site-listing')]/div[contains(@class, 'td') and contains(@class, 'right')][3]")
https://bet.hkjc.com/racing/pages/odds_wp.aspx?lang=ch&date=2021-01-27&venue=HV&raceno=1
回覆刪除想取這個的獨嬴及位置 ,但貼上XPATH 之後都取不到,請問要怎樣做