![]()
很久以前就註冊了帳號,但一直都沒認真使用 :P 而後 GAE 又多了 Cron Jobs,我還是沒有用。最近提起勁來用一下吧!此篇只著重在 local 端的 python 練習。
練習的功能:
- 設定 CLI 相容環境(command mode 可以測試 script.py 而不用每次都從瀏覽器執行)
- 使用 urllib2 取得網路資料
- 使用 re 取得資料(Regular Expression 處理字串)
- 使用 urlfetch 存取網路服務(google.appengine.api)
- 實現 urlfetch with cookie 功能
- 使用 plurk api 發布消息
流程:
先在 Windows 7 環境上,使用 googleappengine lib 寫寫 python 程式,接著從某個 url 取得資料,再用 re 處理字串,然後使用 plurk api 發布訊息。上述流程沒問題後,改成 CGI 模式,因此可透過 GAE 來執行,最後設定 cron jobs
安裝 GAE 相關開發環境:
- GoogleAppEngine-1.6.2.msi
- python-2.5.msi
- npp.5.9.8.Installer.exe
- google-appengine-docs-20120131.zip (GAE離線文件)
一切都用預設安裝,別忘了設定環境變數,在 cmd mode 下才可以直接打 python 來做事
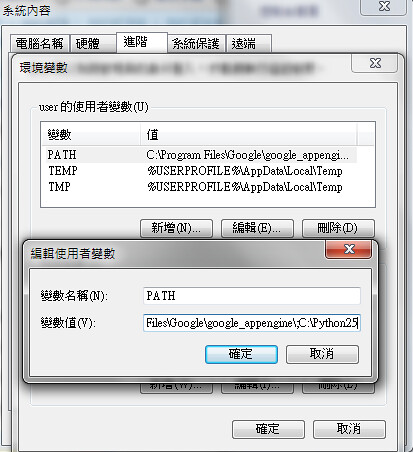
建立一個 GAE Project:
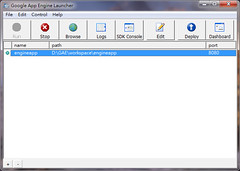
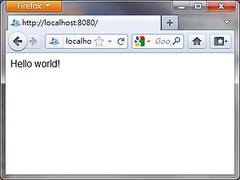
僅本地端,除了 Project 位置外(D:\GAE\workspace\engineapp),全部都預設,弄完就開起來測試一下,理論上應該可以輕易地用瀏覽器瀏覽這 hello world 程式
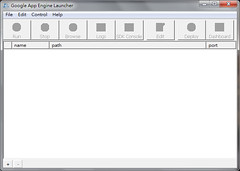
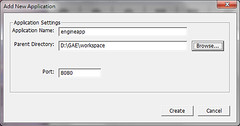
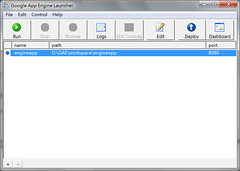
新增一支 script (plurk.py):
在 Project 位置建立一個 plurk.py 空檔案,接著就切到 command mode 來測試:
C:\> D:
D:\> cd GAE\workspace\engineapp
D:\GAE\workspace\engineapp>python plurk.py
(...沒東西...)
設置 script 可使用 GAE Libs:
# -*- coding: utf-8 -*-
"""
# ImportError: No module named google.appengine.api
import sys, os
DIR_PATH = 'C:\Program Files\Google\google_appengine'
EXTRA_PATHS = [
DIR_PATH,
os.path.join(DIR_PATH, 'lib', 'antlr3'),
os.path.join(DIR_PATH, 'lib', 'django'),
os.path.join(DIR_PATH, 'lib', 'django_0_96','django'),
os.path.join(DIR_PATH, 'lib', 'django_1_2','django'),
os.path.join(DIR_PATH, 'lib', 'django_1_3','django'),
os.path.join(DIR_PATH, 'lib', 'simplejson'),
os.path.join(DIR_PATH, 'lib', 'fancy_urllib'),
os.path.join(DIR_PATH, 'lib', 'ipaddr'),
os.path.join(DIR_PATH, 'lib', 'webob'),
os.path.join(DIR_PATH, 'lib', 'yaml', 'lib'),
]
sys.path = EXTRA_PATHS + sys.path
# AssertionError: No api proxy found for service "urlfetch"
from google.appengine.api import apiproxy_stub_map
from google.appengine.api import datastore_file_stub
from google.appengine.api import mail_stub
from google.appengine.api import urlfetch_stub
from google.appengine.api import user_service_stub
APP_ID = u'test_app'
#os.environ['AUTH_DOMAIN'] = AUTH_DOMAIN # gmail.com
#os.environ['USER_EMAIL'] = LOGGED_IN_USER # account@gmail.com
apiproxy_stub_map.apiproxy = apiproxy_stub_map.APIProxyStubMap()
# Use a fresh stub datastore.
stub = datastore_file_stub.DatastoreFileStub(APP_ID, '/dev/null', '/dev/null')
apiproxy_stub_map.apiproxy.RegisterStub('datastore_v3', stub)
# Use a fresh stub UserService.
apiproxy_stub_map.apiproxy.RegisterStub('user',user_service_stub.UserServiceStub())
# Use a fresh urlfetch stub.
apiproxy_stub_map.apiproxy.RegisterStub('urlfetch', urlfetch_stub.URLFetchServiceStub())
# Use a fresh mail stub.
apiproxy_stub_map.apiproxy.RegisterStub('mail', mail_stub.MailServiceStub())
"""
把這一段擺在 plurk.py 的最上面,如此一來,當你是在 command mode 上執行時,把這段註解打開即可使用(把一開始跟最後的 """ 去掉即可)
接著撰寫 Plurk API 要用的範例程式:
參考 [PHP] 使用官方 Plurk API 實作簡單的機器人 - 靠機器人救 Karma!以 Yahoo News 為例 架構,改成 GAE Python 版,分別實作三個主要 function:
- def getNews()
- 取得新聞
- def doAct()
- 執行 url/api
- def getTinyURL(src)
- 取得縮網址
程式碼:
# return responseContent
def doAct( targetURL, method='POST', data={}, cookie = None, header=None ):
rawHeader = {'User-Agent':'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'}
if header:
rawHeader = header
# load cookie
try:
if cookie <> None:
cookieData = '' # {}
for c in cookie.values():
#cookieData[c.key]=c.value
cookieData += c.key + "=" + c.value
if len(cookieData) > 0 :
rawHeader['Cookie'] = cookieData
except Excetion, e:
pass
# post data
try:
if data and len(data) > 0 :
data = urllib.urlencode( data )
else:
data = None
except Excetion, e:
data = None
rawMehtod = urlfetch.POST if method != 'GET' else urlfetch.GET
response = urlfetch.fetch(url=targetURL,payload=data,method=rawMehtod,headers=rawHeader,deadline=10)
if cookie <> None:
cookie.load(response.headers.get('set-cookie', ''))
return response.content if response <> None and response.content <> None else ''
# return {'status':'ok','data':[ {'title':NewsTitle, 'url':NewsURL } , ... ]}
def getNews():
out = {'status':'fail','data':None}
try:
# setting
newsURL = 'http://tw.yahoo.com/'
newsPatternBeginChecker = '<label class="img-border clearfix">'
newsPatternEndChecker = '<ol class="newsad clearfix">'
newsRePatternNewsExtract = '<h3[^>]*>[^<]*<a href="(.*?)"[^>]*>(.*?)</a></h3>'
#newsRePatternNewsExtract = r'<h3[^>]*>[^<]*<a href="(?P<url>.*?)"[^>]*>(?P<title>.*?)</a></h3>'
newsReOptionsNewsExtract = re.DOTALL
newsPatternURLChecker = 'http:'
raw = urllib2.urlopen(newsURL).read()
checker = str(raw).find(newsPatternBeginChecker)
if checker < 0:
out['data'] = 'newsPatternBeginChecker fail'
return out
raw = raw[checker+len(newsPatternBeginChecker):]
checker = raw.find(newsPatternEndChecker)
if checker < 0:
out['data'] = 'newsPatternEndChecker fail'
return out
raw = raw[:checker]
#print "##",raw,"##"
m = re.findall( newsRePatternNewsExtract, raw, newsReOptionsNewsExtract )
if m:
out['data'] = []
for data in m:
urlChecker = data[0].find(newsPatternURLChecker)
if urlChecker >= 0:
out['data'].append( {'title':data[1],'url':data[0][urlChecker:]} )
if len(out['data']) > 0:
out['status'] = 'ok'
else:
out['data'] = 'not found'
except Exception, e:
out['data'] = str(e)
return out
# return short url via tinyurl.com
def getTinyURL(src):
try:
raw = urllib2.urlopen('http://tinyurl.com/api-create.php?'+urllib.urlencode({'url':src})).read()
return raw.strip()
except Exception, e:
pass
return None
呼叫方式:
# main
plurkAPIKey = 'YourPlurkAPIKey'
plurkID = 'YourPlurkID'
plurkPasswd = 'YourPlurkPassword'
getNewsData = getNews()
runLog = []
if getNewsData['status'] == 'ok':
# try login
baseCookie = Cookie.SimpleCookie()
loginData = {'api_key':plurkAPIKey,'username':plurkID,'password':plurkPasswd}
checkLogin = doAct( 'http://www.plurk.com/API/Users/login', 'POST', loginData, baseCookie )
try:
obj = simplejson.loads(checkLogin)
if 'error_text' in obj:
runLog.append( 'login error: '+str(obj['error_text']) )
except Exception,e :
runLog.append( 'login exception: '+str(e) )
if len(runLog) == 0:
# try post
for news_info in getNewsData['data']:
formated_message = '[News] '+news_info['url']+' ('+news_info['title']+')'
if len(formated_message) > 140:
shortURL = getTinyURL(news_info['url'])
if shortURL <> None:
formated_message = '[News] '+shortURL+' ('+news_info['title']+')'
if len(formated_message) <= 140:
writeData = {'api_key':plurkAPIKey,'qualifier':'shares','content':formated_message}
checkPost = doAct( 'http://www.plurk.com/API/Timeline/plurkAdd' , 'POST' , writeData, baseCookie )
try:
obj = simplejson.loads(checkPost)
if 'error_text' in obj and obj['error_text'] <> None:
runLog.append( 'post error: '+str(obj['error_text'])+', Message:'+formated_message )
except Exception, e:
runLog.append( 'post exception: '+str(e)+', Message:'+formated_message )
else:
runLog.append( 'getNews error:'+getNewsData['data'])
若單純測試 Plurk API 的話,只要依序執行這兩段即可:
# try login
baseCookie = Cookie.SimpleCookie()
loginData = {'api_key':plurkAPIKey,'username':plurkID,'password':plurkPasswd}
print doAct( 'http://www.plurk.com/API/Users/login', 'POST', loginData, baseCookie )
# try post
writeData = {'api_key':plurkAPIKey,'qualifier':'shares','content':'Hello World'}
print doAct( 'http://www.plurk.com/API/Timeline/plurkAdd' , 'POST' , writeData, baseCookie )
弄成 CGI 模式:
# ...依序把上面的程式碼都湊在一起後,接著下面這段...
# CGI FORMAT for HTML
print 'Content-Type: text/html'
print ''
# report
print '<html><head><meta http-equiv="content-type" content="text/html; charset=utf-8"/></head><body>'
if len(runLog) > 0:
print "<pre>"
#print runLog
print "</pre>"
for err in runLog:
print '<p>'+ err + '</p>'
else:
print 'OK'
print '</body></html>'
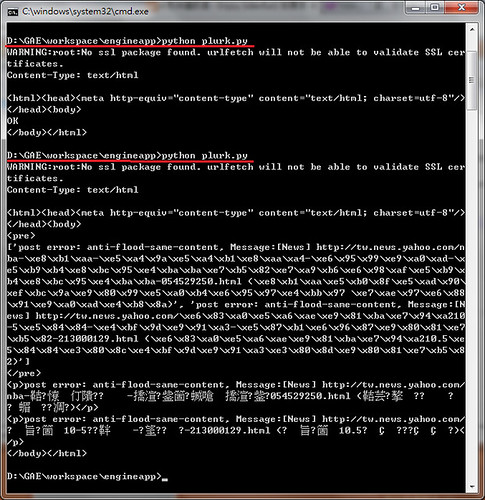
如此一來,就是相容於瀏覽器跟 command mode 的環境:
此為連續執行 2~3 次的結果,因為 Plurk 會擋重複訊息,所以第二次輸出的結果不一樣
設定 GAE Project (engineapp):
設定對應的 URL 位置:
engineapp\app.yaml:
application: engineapp
version: 1
runtime: python
api_version: 1
handlers:
- url: /favicon\.ico
static_files: favicon.ico
upload: favicon\.ico
- url: /PlrukPost
script: plurk.py
- url: .*
script: main.py
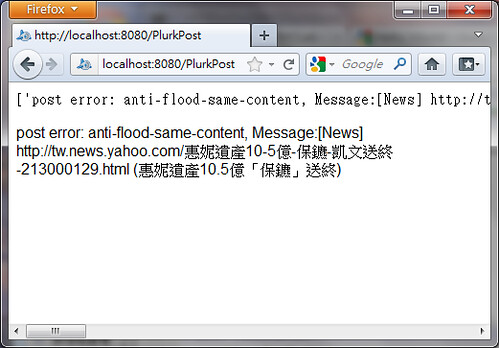
如此就可以用網頁瀏覽:
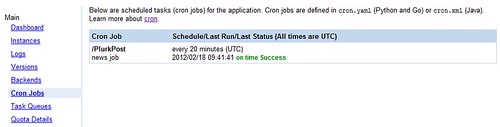
設定 Cron Jobs:
engineapp\cron.yaml:
cron:
- description: news job
url: /PlurkPost
schedule: every 20 minutes
這樣每 20 分鐘就會去瀏覽該網頁一次,自然就會執行工作一次,此部分需要上傳到 GAE 上才能
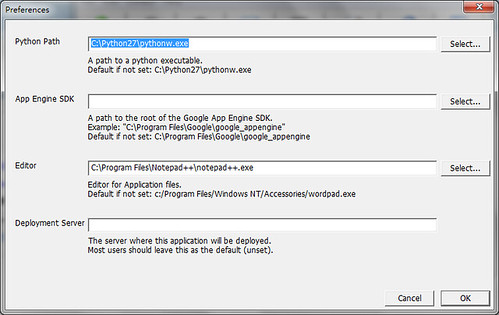
Deploy 筆記:
在 Google App Engine 的文件上,以 Python 2.5 為例,然而在使用 Deploy 時,會看到 ssl module not found 的訊息,因此無法上傳到 server。最簡單的解法就是安裝一下 Python 2.7 版,接著在 Google App Engine Launcher -> Edit -> Preferences 指定 Python Path ,就能夠順利上傳囉!
沒有留言:
張貼留言