幾年前有幸參加過數據分析的黑客松,但是太耍廢了 XD 當下只用統計硬幹。最近有些閒情想好好認識一下 SVM 了。目前使用它的方式很粗淺 XD 就是把一堆 feature 湊個成 array 餵進去跑,接著就有報表可以看了(當初還人工去計算 precision / recall),回想起來真是青春啊
回過頭來,程式架構如下:
import numpy as np
import pandas as pd # 假設 input 是 csv 格式
# 讀取資料中
raw = pd.read_csv("input.csv")
# 可以得知有多少欄位可以用
print(raw.columns)
# 假設所有屬性都是可以有一對一的對應,全部把他們取代成整數,此為 HASH table 用來轉換而已
LOOK_FIELD = {}
# 假設 raw 有一萬筆資料
USE_DATA_COUNT = 10000 # or raw.size
# 將 raw 資料建置成 numpy array 架構
data_input = None
data_output = None
for index, row in raw.iterrows():
data_per_row = np.empty([])
# 將有興趣的欄位(feature)抽出來使用
for field_name in [
"csv_fieldname1",
"csv_fieldname2",
]:
field_data = np.zeros(1, dtype=np.int)
if field_name not in LOOK_FIELD:
LOOK_FIELD[field_name] = {}
if row[field_name] in LOOK_FIELD[field_name]:
field_data[0] = LOOK_FIELD[field_name][row[field_name]]
else:
field_data[0] = len(LOOK_FIELD[field_name])
LOOK_FIELD[field_name][row[field_name]] = field_data[0]
data_per_row = np.append(data_per_row, field_data.reshape(1, -1))
if data_input is None:
data_input = np.zeros([USE_DATA_COUNT, data_per_row.reshape(1, -1).size], dtype=np.float)
data_input[index] = data_per_row.reshape(1, -1)
result = np.zeros([1], dtype=np.int)
output_field_name = "csv_fieldname3"
# 將 結果 的欄位轉換成數值
if output_field_name not in LOOK_FIELD:
LOOK_FIELD[output_field_name] = {}
if row[output_field_name] in LOOK_FIELD[output_field_name]:
result[0] = LOOK_FIELD[output_field_name][ row[output_field_name] ]
else:
result[0] = len(LOOK_FIELD[output_field_name])
LOOK_FIELD[output_field_name][ row[output_field_name] ] = result[0]
if data_output is None:
data_output = np.zeros([USE_DATA_COUNT, result.reshape(1, ).size], dtype=np.int)
data_output[index] = result.reshape(1, )
# 支援只使用 USE_DATA_COUNT 筆資料
if index >= USE_DATA_COUNT - 1:
break
print(data_input)
print(data_output)
print(data_input.shape)
print(data_output.shape)
from sklearn import svm, metrics
classifier = svm.SVC()
# 使用 1/5 的資料來訓練
number_of_data_to_learn = int(USE_DATA_COUNT / 5) # or int(data_output.size/5)
# start to learn
classifier.fit(data_input[:number_of_data_to_learn], data_output[:number_of_data_to_learn])
# get the result
expected = data_output[number_of_data_to_learn:]
predicted = classifier.predict(data_input[number_of_data_to_learn:])
# get the report
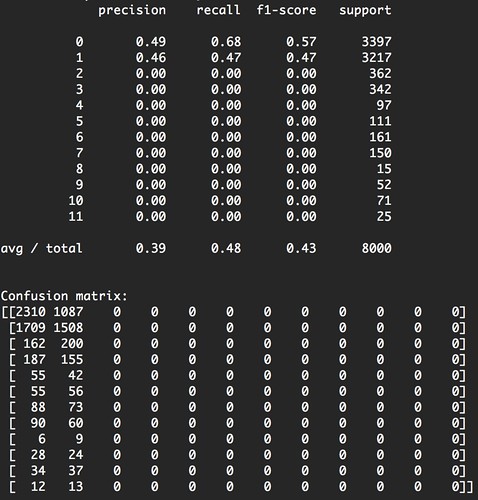
print("Classification report for classifier %s:\n%s\n" % (classifier, metrics.classification_report(expected, predicted)))
print("Confusion matrix:\n%s" % metrics.confusion_matrix(expected, predicted))
透過上述的程式架構,未來就只要把資料轉成 csv ,挑挑 feature (csv_fieldname1, csv_fieldname2) 跟 output (csv_fieldname3) 欄位就可以快速看到成果了 XD 要唬人也可以 3 分鐘就弄出點東西。
沒有留言:
張貼留言