在數據分析的比賽,默認的資料多是 csv 格式,接著用 panda 讀取,再用 seaborn 和 matplotlib.pyplot 繪圖。透過第一步的視覺化,快速得知數據分佈狀態,甚至在
輸入資料:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
5 25.29 4.71 Male No Sun Dinner 4
6 8.77 2.00 Male No Sun Dinner 2
7 26.88 3.12 Male No Sun Dinner 4
8 15.04 1.96 Male No Sun Dinner 2
9 14.78 3.23 Male No Sun Dinner 2
10 10.27 1.71 Male No Sun Dinner 2
11 35.26 5.00 Female No Sun Dinner 4
12 15.42 1.57 Male No Sun Dinner 2
13 18.43 3.00 Male No Sun Dinner 4
14 14.83 3.02 Female No Sun Dinner 2
15 21.58 3.92 Male No Sun Dinner 2
16 10.33 1.67 Female No Sun Dinner 3
17 16.29 3.71 Male No Sun Dinner 3
18 16.97 3.50 Female No Sun Dinner 3
19 20.65 3.35 Male No Sat Dinner 3
20 17.92 4.08 Male No Sat Dinner 2
21 20.29 2.75 Female No Sat Dinner 2
22 15.77 2.23 Female No Sat Dinner 2
23 39.42 7.58 Male No Sat Dinner 4
24 19.82 3.18 Male No Sat Dinner 2
25 17.81 2.34 Male No Sat Dinner 4
26 13.37 2.00 Male No Sat Dinner 2
27 12.69 2.00 Male No Sat Dinner 2
28 21.70 4.30 Male No Sat Dinner 2
29 19.65 3.00 Female No Sat Dinner 2
.. ... ... ... ... ... ... ...
214 28.17 6.50 Female Yes Sat Dinner 3
215 12.90 1.10 Female Yes Sat Dinner 2
216 28.15 3.00 Male Yes Sat Dinner 5
217 11.59 1.50 Male Yes Sat Dinner 2
218 7.74 1.44 Male Yes Sat Dinner 2
219 30.14 3.09 Female Yes Sat Dinner 4
220 12.16 2.20 Male Yes Fri Lunch 2
221 13.42 3.48 Female Yes Fri Lunch 2
222 8.58 1.92 Male Yes Fri Lunch 1
223 15.98 3.00 Female No Fri Lunch 3
224 13.42 1.58 Male Yes Fri Lunch 2
225 16.27 2.50 Female Yes Fri Lunch 2
226 10.09 2.00 Female Yes Fri Lunch 2
227 20.45 3.00 Male No Sat Dinner 4
228 13.28 2.72 Male No Sat Dinner 2
229 22.12 2.88 Female Yes Sat Dinner 2
230 24.01 2.00 Male Yes Sat Dinner 4
231 15.69 3.00 Male Yes Sat Dinner 3
232 11.61 3.39 Male No Sat Dinner 2
233 10.77 1.47 Male No Sat Dinner 2
234 15.53 3.00 Male Yes Sat Dinner 2
235 10.07 1.25 Male No Sat Dinner 2
236 12.60 1.00 Male Yes Sat Dinner 2
237 32.83 1.17 Male Yes Sat Dinner 2
238 35.83 4.67 Female No Sat Dinner 3
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
繪出資料分佈/密布圖:
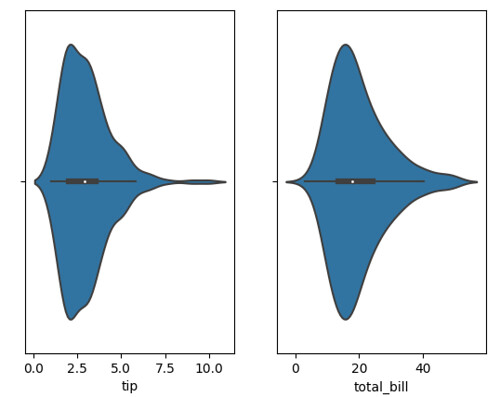
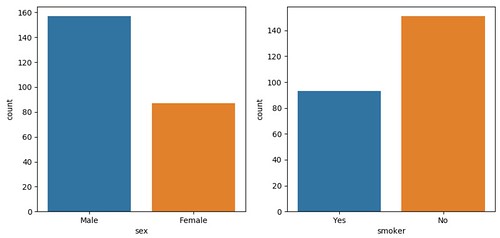
繪出資料筆數:
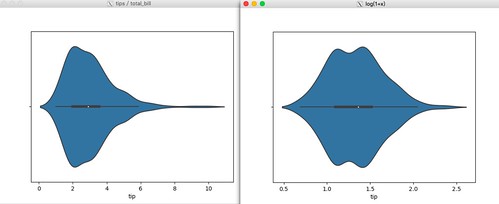
繪出 log(1+x) 的效果(以 tip 為例):
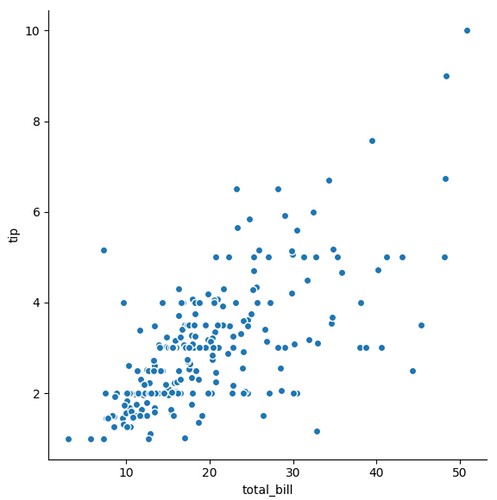
兩兩欄位計算相關性,並繪出分佈圖:
程式碼:
import matplotlib.pyplot as plt
import seaborn as sns
tips = sns.load_dataset("tips")
print(tips)
# https://seaborn.pydata.org/generated/seaborn.violinplot.html
plt.figure('tips / total_bill')
plt.subplot(1,2,1)
sns.violinplot(data=tips, x='tip')
plt.subplot(1,2,2)
sns.violinplot(data=tips, x='total_bill')
# https://seaborn.pydata.org/generated/seaborn.countplot.html
plt.figure('sex / smoker')
plt.subplot(1,2,1)
sns.countplot(data=tips,x='sex')
plt.subplot(1,2,2)
sns.countplot(data=tips,x='smoker')
import numpy as np
plt.figure('log(1+x)')
# https://docs.scipy.org/doc/numpy/reference/generated/numpy.log1p.html
tips['tip'] = np.log1p(tips['tip'])
sns.violinplot(data=tips, x='tip')
# https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.corr.html
data_corr = tips.corr()
print(data_corr)
threshold = 0.5
corr_list = []
size = data_corr.shape[0]
for i in range(0,size):
for j in range(i+1,size):
if (data_corr.iloc[i,j] >= threshold and data_corr.iloc[i,j] < 1) or (data_corr.iloc[i,j] < 0 and data_corr.iloc[i,j] <= -threshold):
corr_list.append([data_corr.iloc[i,j],i,j])
s_corr_list = sorted(corr_list,key=lambda x: -abs(x[0]))
print(s_corr_list)
cols=data_corr.columns
for v,i,j in s_corr_list:
print ("%s and %s = %.2f" % (cols[i],cols[j],v))
sns.pairplot(tips, size=6, x_vars=cols[i],y_vars=cols[j] )
plt.show()
最後,有時資料內有垃圾需要清除後在繪圖,可以善用 pandas.DataFrame.dropna 來過濾資料:
# https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.dropna.html
# 繪圖時,刪除 nan 的資料
newdata = rawdata.dropna(axis=0)
sns.violinplot(newdata)
# https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html
# 繪圖時,只關注特定範圍的資料(此例:總額 < 20 都刪除不繪)
newdata = tips.drop(tips[ tips.total_bill < 20 ].index)
sns.violinplot(data=newdata, x='tip')
沒有留言:
張貼留言