前陣子一直在調校 Javascript & Unzip 的事情,找到一個滿貼切工作的 -- Booktorious ,並且開始修改它。只是再怎樣地修改,在 Mobile Device 都不太適用,也被提醒會不會挑到的程式沒有實做很好,這部份我有留意它 unzip 的部份,的確存在不少可以精進的地方,當我準備要改得時候,我又看到了 rePublish 裡頭用的 zip 其實就已經接近我要改善的方式,因此筆記一下比較的過程,之後有空再慢慢增加其他對應的 library。
整個過程,看起來有點線性的成長,隨著檔案大小的增加,解壓縮的時間也會接近倍數成長。而 Booktorious 之 js-unzip 裡頭,有用到大量的資料複製,所以時間上花費會更多,相對於 rePublish 之 zip 的使用,對於 raw data 採用紀錄 offset 的方式,因此比 Booktorious 更加接近線性關係。
函式庫:
測資(純粹看 size 關係而非內容或檔案數目):
- EPUB - Alice's Adventures in Wonderland (91KB)
- EPUB - Dream Merchant (929KB)
- EPUB - Well Played 1.0: Video Games, Value and Meaning (9.2MB)
@ AMD X4 955, Ubuntu 10.04 i386, DDR3-1333 4GB, Google Chrome 6.0.495.0 dev
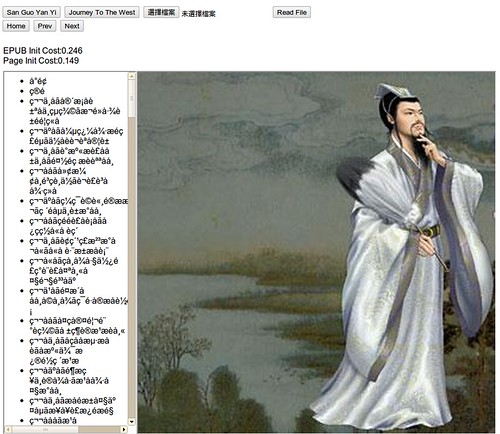
91KB
0.034s @ [js-zip & js-inflate]
0.026s @ [zip & inflate]
929KB
0.302s @ [js-zip & js-inflate]
0.139s @ [zip & inflate]
9.2MB
14.945s @ [js-zip & js-inflate]
1.654s @ [zip & inflate]
@ iPad, iOS 3.2.2
91KB
2.182s @ [js-zip & js-inflate]
1.214s @ [zip & inflate]
929KB
JavaScript execution exceeded timeout @ [js-zip & js-inflate]
7.177s @ [zip & inflate]
9.2MB
JavaScript execution exceeded timeout @ [js-zip & js-inflate]
JavaScript execution exceeded timeout @ [zip & inflate]
@ iPhone 3G, iOS 4.0.2
91KB
8.438s @ [js-zip & js-inflate]
5.397s @ [zip & inflate]
929KB
JavaScript execution exceeded timeout @ [js-zip & js-inflate]
JavaScript execution exceeded timeout @ [zip & inflate]
9.2MB
JavaScript execution exceeded timeout @ [js-zip & js-inflate]
JavaScript execution exceeded timeout @ [zip & inflate]
以下是實驗的 Source Code,而測試中如果瀏覽器已經等很久甚至產生 timeout 的訊息時,試著一次只測試一個 library 吧,並且在 iPad 或 iPhone 也有機會碰到直接跳出 Safari 的情況
@index.html
<!DOCTYPE html>
<html xml:lang="utf-8" lang="utf-8" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<script type="text/javascript" src="js-unzip.js"></script>
<script type="text/javascript" src="js-inflate.js"></script>
<script type="text/javascript" src="zip.js"></script>
<script type="text/javascript" src="inflate.js"></script>
</head>
<body>
<script language="Javascript">
function report( s, clear )
{
var report = document.getElementById( 'report' );
if( clear )
while ( report.hasChildNodes() && report.childNodes.length >= 1 )
report.removeChild( report.firstChild );
if( s )
{
report.appendChild( document.createTextNode( s ) );
report.appendChild( document.createElement( 'br' ) );
}
}
function doZip( epub , choose )
{
var path = epub || "epub/91kb.epub";
var ajReq = new XMLHttpRequest();
try{
ajReq.open( 'GET' , path , false );
ajReq.overrideMimeType( 'text/plain; charset=x-user-defined' );
ajReq.send(null);
ajReq.overrideMimeType( 'text/plain; charset=UTF-8' );
var out = ajReq.responseText || '' ;
var out_array = [];
for( var i=0, len=out.length, scc=String.fromCharCode ; i<len ; ++i )
out_array[i] = scc( out.charCodeAt(i) & 0xff );
var out_binary = out_array.join( '' );
if( out_binary !== '' )
{
var cost ;
var unzipper;
report( null, true );
//
// js-unzip & js-inflate
//
if( !choose || choose === 1 )
{
unzipper = null;
cost = new Date();
unzipper = new JSUnzip( out_binary );
if( unzipper.isZipFile() )
{
unzipper.readEntries();
for (var i = 0 , len = unzipper.entries.length; i < len ; i++)
{
if ( unzipper.entries[i].compressionMethod === 0)
; // unzipper.entries[i].data
else if ( unzipper.entries[i].compressionMethod === 8)
JSInflate.inflate( unzipper.entries[i].data );
}
}
cost = new Date() - cost ;
report( (cost / 1000.0) + 's' + ' @ [js-zip & js-inflate]' );
}
//
// zip & inflate
//
if( !choose || choose === 2 )
{
unzipper = null;
cost = new Date();
unzipper = Zip;
unzipper.Archive( out_binary );
for (var i = 0 , len = unzipper.entries.length; i < len ; i++)
unzipper.entries[i].content();
cost = new Date() - cost ;
report( (cost / 1000.0) + 's' + ' @ [zip & inflate]' );
}
}
}catch( err ){
alert( 'Error:' + err );
}
}
</script>
<dl>
<dt>Do all</dt>
<dd><button onclick="doZip( 'epub/91kb.epub' );">Unzip 91KB</button></dd>
<dd><button onclick="doZip( 'epub/929kb.epub' );">Unzip 929kB</button></dd>
<dd><button onclick="doZip( 'epub/9.2mb.epub' );">Unzip 9.2MB</button></dd>
</dl>
<dl>
<dt>Use Booktorious</dt>
<dd><button onclick="doZip( 'epub/91kb.epub' , 1 );">Unzip 91KB</button></dd>
<dd><button onclick="doZip( 'epub/929kb.epub' , 1 );">Unzip 929kB</button></dd>
<dd><button onclick="doZip( 'epub/9.2mb.epub' , 1 );">Unzip 9.2MB</button></dd>
</dl>
<dl>
<dt>Use rePublish</dt>
<dd><button onclick="doZip( 'epub/91kb.epub' , 2 );">Unzip 91KB</button></dd>
<dd><button onclick="doZip( 'epub/929kb.epub' , 2 );">Unzip 929kB</button></dd>
<dd><button onclick="doZip( 'epub/9.2mb.epub' , 2 );">Unzip 9.2MB</button></dd>
</dl>
<p id="report"></p>
</body>
</html>